
After a decade of running Hive queries on their data lakes, many companies are astonished at the speeds in which they are able to query their existing Hive tables by just replacing Hive with Starburst. Business analysts and data scientists are now empowered to interactively comb their data using Starburst rather than exporting a subset of the data in multiple painstaking phases. With Starburst’s collection of open source and enterprise connectors, you can quickly run federated queries with your data lake without having to move the entire dataset into your data lake! So how does the query engine achieve this level of performance that enables such productivity? In this blog we’re going to dive into arguably the quintessential use case of the Starburst query engine to gain an insight into the answer to this question.
To many, it’s difficult to understand why Hive became so popular due to how slow it operates. It’s impossible to fully understand the answer to this question without considering that it was engineered during the earlier days of Big Data. Hive was built on the same initial premise that fault tolerance was a necessity to processing big data and its goal was more about making the queries much simpler to write for those not interested in writing complicated MapReduce jobs. In other words, Hive’s primary purpose was to lower the barrier to entry for analysts but was not particularly concerned with running the MapReduce jobs any faster.
This resulted in years of data analysts writing a query and running it for hours before they realized a small part of the data was in an unexpected format causing the entire query to fail. These types of issues and the general frustration and experience of using Hive still left data consumers wanting more in order to be successful and productive in their work. A large part of this slowness is due to the frameworks that Hive runs on. Frameworks like Hadoop were designed to run jobs for longer periods of time. Starting and stopping a MapReduce would take minutes and the actual processing was slowed down when queries would be halted to write to disk to checkpoint. All of this would happen for the largest of queries running over petabytes of data, to the smallest queries running over megabytes of data.
With all of these extra steps being taken, new methodologies were considered and many started to re-envision these workloads to consider human interaction, data exploration, as well as, speeding up various batch jobs that weren’t reliant on fault tolerance measures. In 2012 Martin, Dain, David, and Eric realized such a system they called Presto, but was rebranded as Trino in late 2020. Trino aims to solve this issue by removing the fault tolerance requirement and building the query engine from scratch. Outside of this one major change from older big data systems, they applied a new level of engineering rigor to designing this system. In order to achieve interactive queuing speeds at petabyte scale they created Trino to be a massively parallel processing (MPP) query engine, meaning it distributed processing of its operations. This distribution is enabled by partitioning the data over an inter-node spread across workers nodes and then over an intra-node scope across threads in a given worker node.
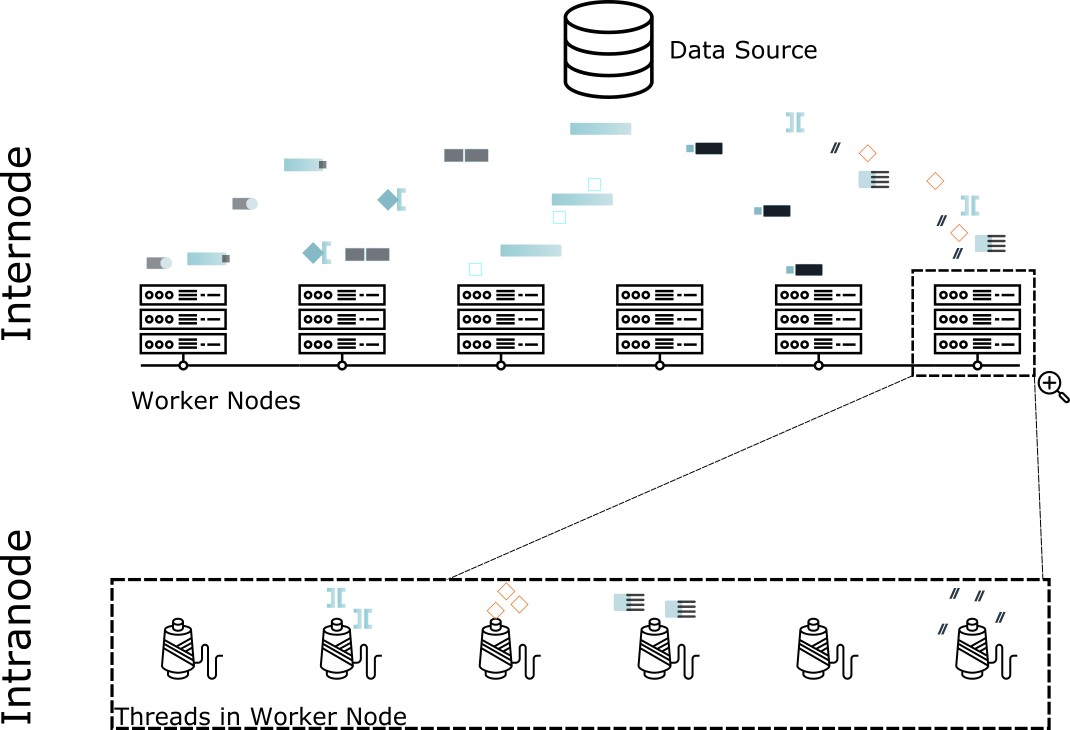
The founders also tapped into well known engineering optimizations like custom generating java byte code to avoid running superfluous instructions that may be generated in more generic code compilation. As the project matured they included useful query engine abstractions such as the cost-based optimizer, that used table and column statistics to aid in the rewriting of the query plan to run efficiently by executing in a manner that reduced the number of overall system IO which leads to faster queries and lower costs.
Giving up fault tolerance doesn’t come without a cost. There are some downsides to not having fault-tolerance if you are running queries that take a particularly long time to run. These are typically batch jobs that require scanning the entire dataset either to augment, process, or move all of the data. These types of operations take a long time for any system as it requires painstakingly combing through all of the data. A system that supports fault tolerance is likely more suitable for these jobs as the time it takes to run it will far surpass the time it takes to checkpoint to disk periodically.
The trade-off Trino makes is that it is aimed to speed up operations that are interactive and only scans data that a user is interested in returning. Since these operations take less time due to less data scanned and the quick turnaround times, if a query fails due to a node, network, or any other failure, there is not too much cost to just running the query again. This is why Trino makes such a useful fit for interactive analytics and even some smaller, shorter running batch jobs. Although Trino has been around for almost a decade, it’s relatively young in the data and analytics space. While it has increased the amount of connectors it supports, the Hive connector is the core connector that many still use. Many users that adopt Trino are still coming from an existing Hive, Impala, Drill, or Spark cluster with goals to speed up their current SQL processing and get an added benefit to run federated queries. Though Hive is definitely the most mature connector, there is still a lot of work being done to increase its performance.
One such feature that exemplifies this growth was introduced to Trino and Starburst in mid-2020 called Dynamic Filtering. This feature was initially added to the Hive connector but has gradually been added to other connectors. For Hive, this feature takes advantage of the known distribution of very large partitioned Hive tables that are partitioned by a specific column.

The common method to perform joins is using a distributed hash-join. The smaller of the two tables gets loaded into memory, while another larger table streams data to the workers with hash tables. Without dynamic filtering, this entire larger table has to be scanned and checked to which node it should get forwarded to based on the hash key. But what if there are only a small portion of the entire set of hash keys that exist on the small table? Why would we want to scan this potentially huge amount of data unnecessarily?
The secret sauce is that the nodes that contain the small table can signal to the nodes steaming from the large table to only pull the data relevant to the necessary subset of partitions. In effect this drastically reduces the amount of data that needs to be scanned and sent to a worker node, only to be discarded. Taking a look at the results from a further improvement called dynamic partition pruning, we see a drastic change in the query turnaround times.
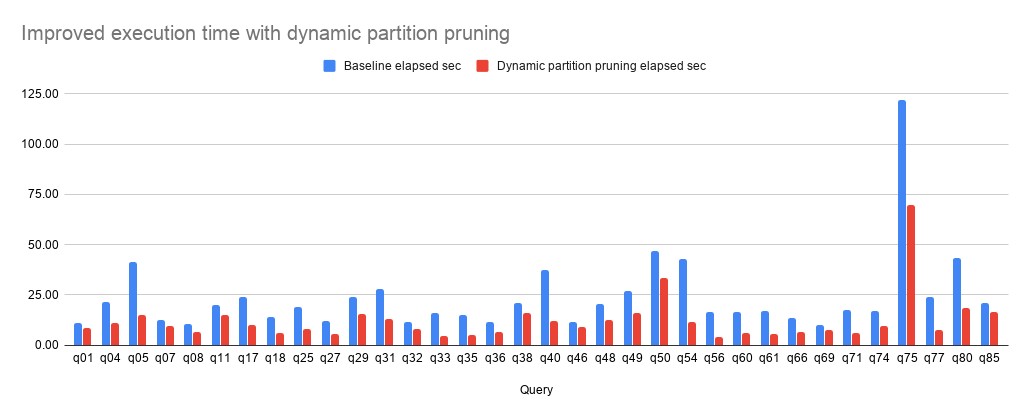
With optimizations like this, combined with the ludicrous speed of an MPP query engine built from the ground up, the Trino and Starburst connectors are able to retrieve data quickly, with fewer operations, and most importantly, with accuracy. While each of these connectors are mostly identical, Starburst offers additional RBAC security via the Ranger plugin, and the Starburst connector is tested for compatibility with major Cloudera and MapR distributions that many of our customers used before they moved to Starburst. For updates on the differences between the Trino Hive connector and the Starburst Hive connector, keep up with this page on the docs.
Hopefully this has helped clarify what makes the Trino Hive connector so fast. If you want to learn more about this connector, see the Gentle Introduction to the Hive Connector article.




