
One of the things that really drew me to and got me excited about Presto over 4 years ago was that it wasn’t tied to any Hadoop distribution. Having worked on numerous, large Hortonworks implementations in the past and forced to use the tools in their ecosystem, I was very excited when I was introduced to Presto which was a stand-alone, open source SQL query engine that could be installed anywhere and wasn’t reliant upon Hadoop infrastructure.
Apache Drill
Case in point is Apache Drill. Although Drill had some nice features such as schema-on-the-fly where you can query data and it determines the structure at query time, but it never really caught on partially because it was tied to MapR (one of the big 3 Hadoop vendors) but more specifically because of performance and concurrency issues. There are companies that have built their products based on Drill and they also suffer from these same performance and concurrency issues and now must look to other projects or continue to develop their product on their own which becomes proprietary at that point.x
Losing Development and Support of Drill

With the recent announcement that HPE (Hewlett Packard Enterprise) will no longer be supporting or contributing to Drill, this is the result of having a query engine tied to an ecosystem such as Hadoop. Other query projects such as Impala and Hive LLAP are also tightly integrated with Hadoop leaving existing users to fear the same fate.
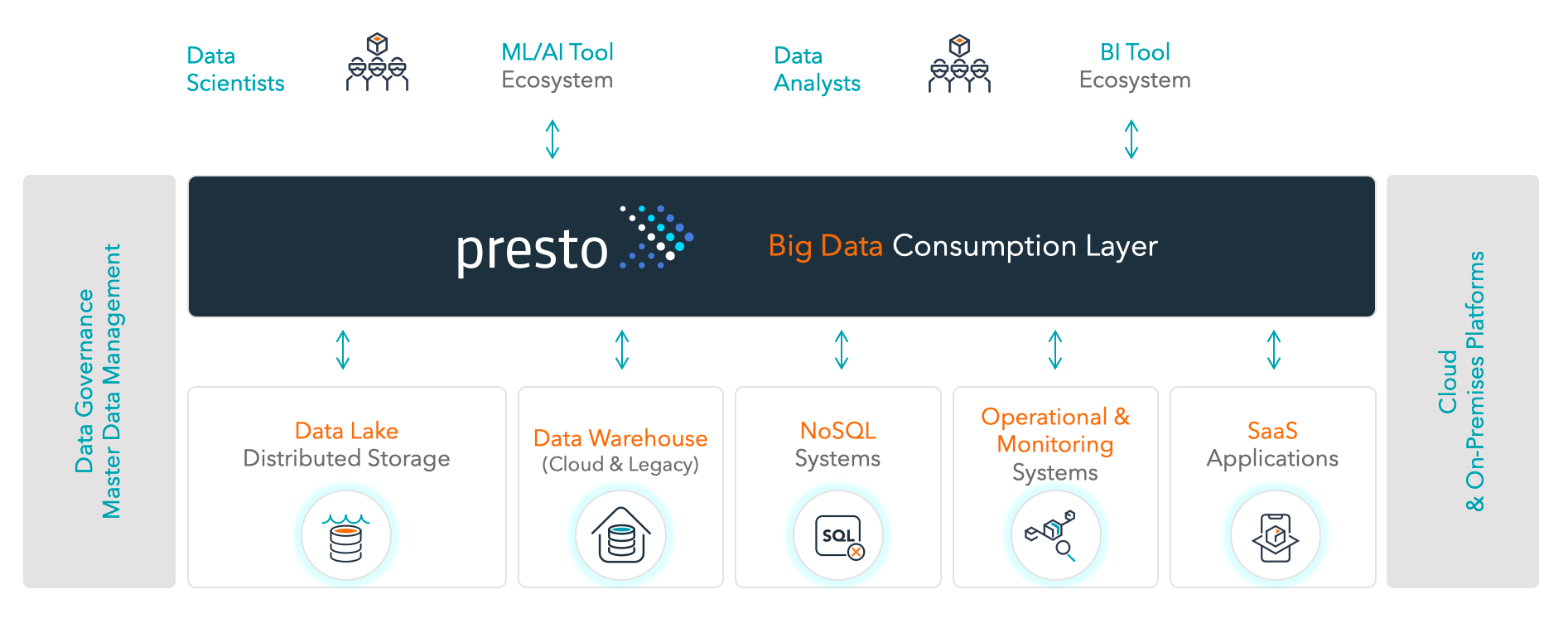
Presto’s Adoption
Presto’s popularity in the last few years has exploded mostly because of the lightweight nature of the architecture as well as how easily it works in any infrastructure including cloud and on-premises. Another great feature of Presto is the ability to federate data from many sources using the wide range of growing connectors and industry standard SQL. These types of use cases have exploded with adoption from many enterprise companies with 100s of legacy systems that still hold valuable data which can be used for analytics.
Proprietary Solutions vs. Open Source
For years companies were stuck pouring money into proprietary solutions and they are looking for solutions that don’t trap them again. Open source software with companies providing support and enterprise features has grown in popularity and provides a level of comfort to companies to avoid product lock-in in the future.
A Future with Presto
The future looks bright for Presto as it’s one of the fastest growing open source projects with over 20,000 commits and over 2500 people on their community Slack channel. There are a tremendous amount of new features being added on a weekly basis. It can be installed and operated on any cloud as well as on-premises to future-proof your architecture so you aren’t left scrambling when your current SQL query engine becomes unsupported.




