
I’m pleased to announce general availability of Starburst Presto 302e, the most exciting and feature rich new Presto release by Starburst to date. When we founded Starburst in 2017, our vision was to enable our customers to query any data, on any platform, at any scale. Today, we’ve taken a big step forward towards realizing that vision.
Before I begin, I’d like to thank all of our customers for helping to shape the roadmap over the past 18 months that has led us to this point. We feel incredibly fortunate to have such a visionary group of Presto enthusiasts that we get to work with every day.
There’s a lot to cover here, so I’ve divided this blog post into 8 parts:
- Starburst Mission Control™: Introducing our brand new management console that allows you to deploy Presto anywhere and query any data source
- Data Connectivity: New connectors including BigQuery, ElasticSearch, and Kudu
- Starburst Presto Security : Updates to RBAC in Presto, including AWS Glue support
- Query Performance & Scale: Presto continues to get faster, with the cost-based query optimizer now supporting AWS Glue stats
- Coordinator HA: This has been available for Starburst customers since the second half of last year, but now we’ve baked it into our AWS offering
- Presto Metrics: AWS Cloudwatch integration
- State Street + Starburst Collaboration: Presto is a community
- What’s Next?
Starburst Mission Control™
Mission Control is a web based management console for Presto that allows you to easily create, access, and manage multiple Presto clusters from a single, unified, easy-to-use console. Mission Control makes it simple for data analysts to seamlessly access the data they need, no matter its location. This capability creates the optimal separation of compute and storage, and provides the freedom to connect to and query any data source, eliminating data vendor lock-in.
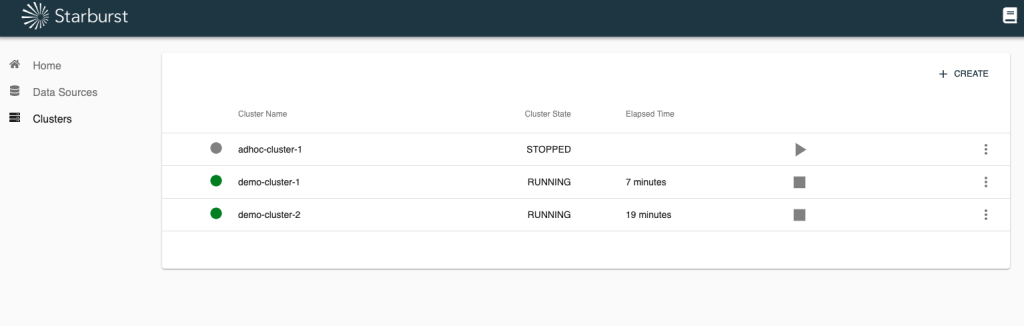
Save your configuration settings and rapidly deploy Presto clusters. Scale up and scale down from the intuitive UI, or set autoscaling to do the work for you.
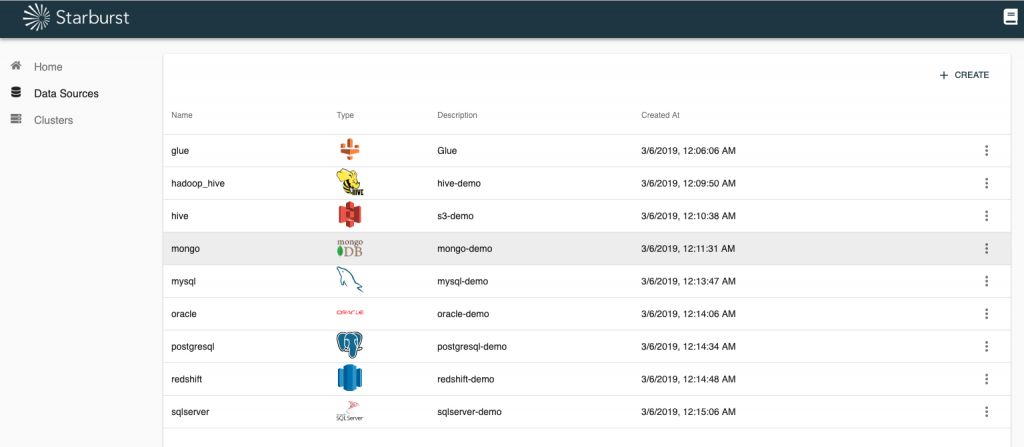
Choose your data sources and connect them to your Presto cluster with the click of a button. You can even connect data sources in different clouds or on-prem data centers.
Starburst Mission Control for Starburst Presto is available immediately for AWS with more platforms and features coming online next quarter. Please contact us using the form at the bottom of the page or at hello@starburstdata.com to try out Starburst Mission Control for Presto on AWS.
Data Connectivity for Starburst
In 302e we’ve introduced connectors and compatibilities to additional data sources further extending using Starburst as your data fabric and query consumption layer.
- The Starburst Google BigQuery Connector allows one to query data from BigQuery using Presto. This connector has been in Beta since December 2018 and used successfully for several of our customers running Presto on the Google Cloud Platform (GCP).
- We also introduced a generic JDBC Connector that allows one to connect to other JDBC data sources not included as named connectors in Presto. This is useful if Presto does not yet provide a connector such as Netezza, DB2, Vertica, Greenplum, and many others. We’ll continue to provide updates on our roadmap for additional connectors. And we’re always interested in hearing your feedback for what connectors to add next.
- The Elasticsearch Connector allows one access to Elasticsearch data from Presto. This was contributed to the Presto community and we now officially support it.
- The Kudu Connector allows one access to Kudu data from Presto. This was contributed to the Presto community and we now officially support it.
- In addition to connectors, we also recognize extending Presto’s function compatibility. In 302e we added Oracle compatibility functions allowing your Oracle users to use the functions they are comfortable with.
Starburst Presto Security
When we first started working on Presto, enterprise security was a large focus. Over the years, we’ve added security features such as Kerberos, LDAP, Encryption in-transit, Apache Ranger integration, Apache Sentry integration, and more. Our commitment to security in Presto continues. In 302, we added security auditing capabilities to log information such as the SQL query and user who submitted.
Additionally, with our Apache Ranger integration one can leverage Apache Ranger and Solr integration for further security auditing. We introduced Apache Ranger integration in mid-2018 and continue to improve on the integration. In 302e, we’ve added the ability to enforce policies on Presto native and user defined functions, added row level filtering, and certified the Apache Ranger integration to enforce policies on objects in AWS Glue Data Catalog.
Query Performance & Scale
Presto was designed from the ground up with performance and scale in mind. Each release continues to add improvements in these areas. In 302, table and column statistics collection via a new ANALYZE command in Presto was added. This ANALYZE command is native to Presto which means you no longer are required to have a Hive installation to leverage statistics collection. Data statistics are needed if you want to leverage the Presto Cost Based Optimizer, a feature we added at the beginning of 2018. Previously, one would need a Hadoop and Hive installation in order to collect the statistics. This was problematic for cloud usage where the data was stored in object storage such as S3, S3 compatible stores, Azure blobs, or Azure Data Lake Store which were not part of Hadoop. Adding the ANALYZE command greatly simplifies your Presto installation. Additionally, we introduced a standalone metastore on our AWS solution to rid you of the requirement to run your own Hive Metastore Service for when you only want to query data in S3.
As an industry first, we also added support to collect and store the table and column statistics in AWS Glue Data Catalog. This functionality is incredibly useful for those using AWS Glue or looking to migrate. Before this feature, it was not possible to leverage both the Cost Based Optimizer and Glue Data Catalog.
Coordinator High Availability
Another industry first is providing Presto Coordinator High Availability. Presto’s architecture relies on a single coordinator and a number of workers. When there is a hardware or software failure on a worker node, the Presto cluster can continue to operate as long as there are additional workers. However, if the coordinator node fails, the entire cluster becomes unavailable even if there are plenty of workers. To alleviate this weak point, we’ve added coordinator high availability into our AWS solution. Using our solution you can specify any number of hot standbys. If a coordinator fails, we will automatically elect a new coordinator. This takes only a matter of seconds once the failure is detected. You also have the option of having a cold standby in which an EC2 node will be automatically provisioned when a failure is detected and elected to be the new coordinator.
Presto Metrics
To provide additional Presto insights, we’ve integrated with AWS CloudWatch. Presto logs and Presto metrics are integrated with this service and stored in a central place. In cloud environments, clusters are generally not available indefinitely and this allows you to keep and analyze the Presto cluster data long after the cluster was shutdown. Additionally, we’ve integrated many of these metrics with AWS CloudWatch dashboards allowing one to visualize these valuable insights. We will continue to add additional metrics to store and integrate with other environment in future releases.
State Street + Starburst Collaboration
At Starburst, we are 100% committed to the community-driven ethos of the Presto project. In that spirit, we frequently partner with other companies who are looking to contribute features and enhancements, and help to shepherd the process from concept to pull request. One such example is our ongoing collaboration with State Street Corporation and their recent work on Presto’s spill to disk feature.
Over the past several months, Atri Sharma from State Street Corporation extended Presto’s spill to disk feature used by Joins and Aggregations to also support SQL Order Bys and Window Functions. In doing so, Atri developed the ability to scale query processing to extremely large amounts of data for these types of SQL queries. This was accomplished by writing intermediate results to disk when there was not enough aggregate memory to keep the processing entirely in memory. On behalf of the Presto community, we would like to thank Atri Sharma and State Street Corporation for working to contribute this feature.
We are continuing to collaborate with State Street Corporation and look forward to several exciting features under development to further advance Presto as a scalable enterprise data warehousing solution.
What’s Next?
The key concept in Presto of decoupling of storage and compute provides you the ability to unlock and discover insights in your data not previously possible. Decoupling storage and compute allows:
- Using Starburst as your Cloud Data Warehouse built on open source technology (i.e. Presto) using open data formats residing in any cloud storage or object storage
- Using Starburst as your query fabric or consumption layer to query and federate data sources across an entire organization through a single interface.
- Using Starburst across hybrid and multi cloud environments allowing you to keep your data according to its security, performance, and cost requirements.
In the coming weeks and months you’ll month you’ll start to see more integrations of Presto into the common environments you use. Our goal is to provide you the optionality whether you run Presto on premises or on the cloud. On Hadoop data, object store data, relational data, or NoSQL data.
If you would like more detail on any of the above, please read the Presto 302e release notes.




